手写数字识别
手写数字识别
手写数字识别
任务输入:一系列手写数字图片,其中每张图片都是28x28的像素矩阵。
任务输出:经过了大小归一化和居中处理,输出对应的0~9的数字标签。
MNIST数据集
MNIST数据集是深度学习领域标准,易用的成熟数据集。
由6万个训练样本和1万个测试样本组成,每个样本都是一张28*28像素的灰度手写数字图片。
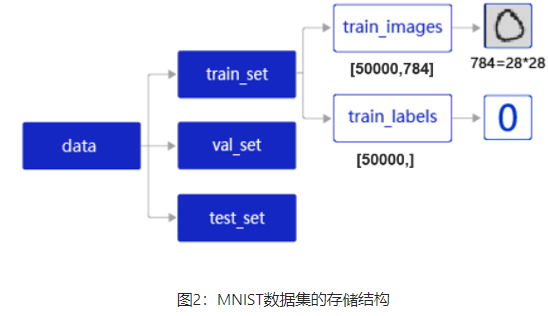
data包含三个元素的列表:train_set、val_set、 test_set,包括50 000条训练样本、10 000条验证样本、10 000条测试样本。每个样本包含手写数字图片和对应的标签。
-
train_set(训练集):用于确定模型参数。
-
val_set(验证集):用于调节模型超参数(如多个网络结构、正则化权重的最优选择)。(验证是否过拟合)
-
test_set(测试集):用于估计应用效果(没有在模型中应用过的数据,更贴近模型在真实场景应用的效果)。
train_set包含两个元素的列表:train_images、train_labels。
-
train_images:[50 000, 784]的二维列表,包含50 000张图片。每张图片用一个长度为784的向量表示,内容是28*28尺寸的像素灰度值(黑白图片)。
-
train_labels:[50 000, ]的列表,表示这些图片对应的分类标签,即0~9之间的一个数字。
极简版
数据处理
-
图像数据是经过归一化,展示前需要缩放回原始数据。(反归一化)
(因为图像的数据集为了方便模型的训练,做过归一化的,想让展现出来的数据使人们看的顺眼,做反归一化)
模型设计
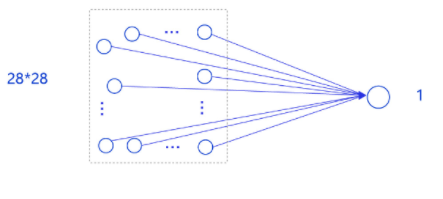
在房价预测深度学习任务中,我们使用了单层且没有非线性变换的模型,取得了理想的预测效果。在手写数字识别中,我们依然使用这个模型预测输入的图形数字值。其中,模型的输入为784维(28×28)数据,输出为1维数据。
-
事实上,采用只有一层的简单网络(对输入求加权和)时并没有处理位置关系信息,因此可以猜测出此模型的预测效果可能有限。
训练配置
训练配置需要先生成模型实例(设为“训练”状态),再设置优化算法和学习率(使用随机梯度下降SGD,学习率设置为0.001)
训练过程
训练过程采用二层循环嵌套方式,训练完成后需要保存模型参数,以便后续使用。
-
内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
-
外层循环:定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置。
配置优化器:SGD Optimizer
模型测试
模型测试的主要目的是验证训练好的模型是否能正确识别出数字,包括如下四步:
-
声明实例
-
加载模型:加载训练过程中保存的模型参数,
-
灌入数据:将测试样本传入模型,模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播。
-
获取预测结果,取整后作为预测标签输出。
在模型测试之前,需要先从'./work/example_0.png'文件中读取样例图片,并进行归一化处理。
从打印结果来看,模型预测出的数字是与实际输出的图片的数字不一致。
展开版
处理数据五大操作
-
读入数据
-
拆分样本集合
-
训练样本集乱序
-
生成批次数据
-
校验数据有效性(图片数量和标签数量相同)
训练样本乱序
-
训练样本乱序: 先将样本按顺序进行编号,建立ID集合index_list。然后将index_list乱序,最后按乱序后的顺序读取数据。
生成批次数据
-
生成批次数据: 先设置合理的batch_size,再将数据转变成符合模型输入要求的np.array格式返回。同时,在返回数据时将Python生成器设置为
yield模式,以减少内存占用。
校验数据有效性
在实际应用中,原始数据可能存在标注不准确、数据杂乱或格式不统一等情况。因此在完成数据处理流程后,还需要进行数据校验,一般有两种方式:
-
机器校验:加入一些校验和清理数据的操作。
-
人工校验:先打印数据输出结果,观察是否是设置的格式。再从训练的结果验证数据处理和读取的有效性。
机器校验:
imgs_length = len(imgs)assert len(imgs) == len(labels), \"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(label))
封装数据读取与处理函数
异步读取数据
-
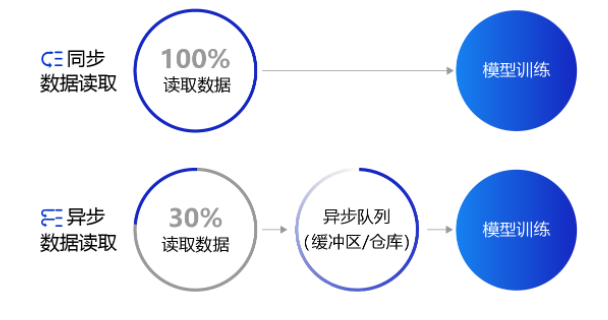
同步数据读取:数据读取与模型训练串行。当模型需要数据时,才运行数据读取函数获得当前批次的数据。在读取数据期间,模型一直等待数据读取结束才进行训练,数据读取速度相对较慢。
-
异步数据读取:数据读取和模型训练并行。读取到的数据不断的放入缓存区,无需等待模型训练就可以启动下一轮数据读取。当模型训练完一个批次后,不用等待数据读取过程,直接从缓存区获得下一批次数据进行训练,从而加快了数据读取速度。
-
异步队列:数据读取和模型训练交互的仓库,二者均可以从仓库中读取数据,它的存在使得两者的工作节奏可以解耦。
capacity:仓库大小容量
return_list:代表数据是不是实时返回
配置网络
无论是牛顿第二定律任务,还是房价预测任务,输入特征和输出预测值之间的关系均可以使用“直线”刻画(使用线性方程来表达)。但手写数字识别任务的输入像素和输出数字标签之间的关系显然不是线性的。
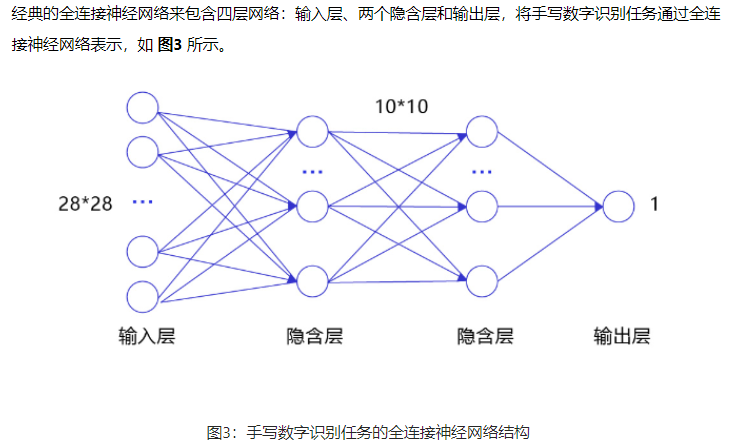
全连接神经网络
-
输入层:将数据输入给神经网络。在该任务中,输入层的尺度为28×28的像素值。
-
隐含层:增加网络深度和复杂度,隐含层的节点数是可以调整的,节点数越多,神经网络表示能力越强,参数量也会增加。在该任务中,中间的两个隐含层为10×10的结构,通常隐含层会比输入层的尺寸小,以便对关键信息做抽象,激活函数使用常见的Sigmoid函数。
-
输出层:输出网络计算结果,输出层的节点数是固定的。如果是回归问题,节点数量为需要回归的数字数量。如果是分类问题,则是分类标签的数量。在该任务中,模型的输出是回归一个数字,输出层的尺寸为1。
隐含层引入非线性激活函数Sigmoid是为了增加神经网络的非线性能力。
分类任务的损失函数
Softmax函数
可以看作将原始输出转变成对应标签的概率,每个输出的范围均在0~1之间,且所有输出之和等于1,这是这种变换后可被解释成概率的基本前提
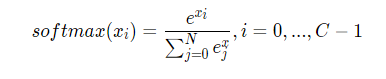
交叉熵
基于最大似然思想:最大概率得到观察结果的假设是真的。 1、数据处理部分:label类型为int64,体现其是标签。 2、输出层改动为10个输出(对应10个标签),并用softmax处理。 3、损失函数由均方误差改为交叉熵。

学习率的主流优化算法
-
SGD(随机梯度)
-
Momentum(篮球)
-
AdaGrad(高尔夫球)
-
Adam(融合Momentum和AdaGrad)
资源配置
通过paddle.set_device API,设置在GPU上训练还是CPU上训练。
分布式训练(多卡)
-
两种并行计算方式
-
模型并行:节省内存,应用较为受限
-
数据并行:飞桨框架采用的实现方式
-
CPU:Pserver通信方式
-
GPU:NCLL通信方式
基于launch启动;
基于spawn方式启动。
-
训练节点上运行同样的程序,以不同的数据做训练。
-
不同训练节点计算的梯度需要聚合
-
-
分类准确率 Accuracy
-
forward 函数加入acc计算并返回结果
-
训练过程中取得该批次样本的acc(与loss不同,无需再做平均)
-
打印acc
检查模型训练过程,识别潜在训练问题
-
校验:使用未参与训练的样本,决策模型超参数
-
测试:使用未参与训练和校验的样本,评估模型的效果
实现:
-
加载参数,模型设置成eval模式
-
读取校验的样本集
-
根据模型预测计算评估指标,需将不同批次的评估结果取平均
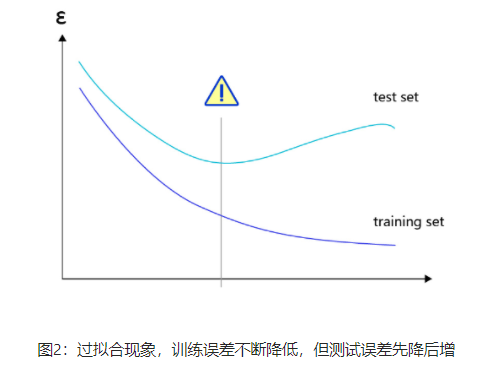
加入正则化项,避免模型过拟合
-
导致过拟合原因
造成过拟合的原因是模型过于敏感,而训练数据量太少或其中的噪音太多。
-
训练数据存在噪音-----数据清洗和修正
-
强大模型(表示空间大) + 训练数据太少 = 在训练数据上表现良好的候选假设太多
-
过拟合:训练集上损失小,验证集或测试集上损失较大(表好模型过于敏感)
-
欠拟合:模型在训练集上和测试集上均损失较大(表示模型不够强大)
正则化
-
目标:防止模型过拟合
-
手段:优化目标中加入正则化项,惩罚参数
-
效果:模型在参数大小和训练集loss之间取得平衡----在预测时效果最好
实现:
-
在优化目标中整体加入正则化项
-
对某一层的参数加入正则化项
泛化能力:表示模型在没有见过的样本上依然有效
在模型的优化目标(损失)中人为加入对参数规模的惩罚项
参数越多或取值越大时,惩罚项就越大
通过调整惩罚项的权重系数,可以使模型在“尽量减少训练损失”和 “保持模型的泛化能力” 之间取得平衡。
附
Fluid
设计用来让用户像 pytorch 和 TensorFlow 一样执行程序。
字典的作用
关键字---值的转换
把 str 转换成 int 函数
tensor
pytorch中训练时所采取的向量格式,图像转换
convert()

resize()
返回改变尺寸的图像的拷贝,重新设定大小
Image.ANTIALIAS
高质量输出
yield
生成器,减少内存占用
只有当用到一批数据的时候,才会执行这样的一个循环
简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后开始。
model(train) 和 model(eval)
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train(),在测试时添加model.eval()。其中model.train()是保证BN层用每一批数据的均值和方差,而model.eval()是保证BN用全部训练数据的均值和方差;而对于Dropout,model.train()是随机取一部分网络连接来训练更新参数,而model.eval()是利用到了所有网络连接。