02.单机数据库
02.单机数据库
文章目录
- 1.数据库
- 2. 过期键
- 3. 过期键的删除策略
- 4. RDB持久化
- 4.1 RDB文件的创建和载入
- 4.2 自动间歇性保存
- 4.3 读取RDB文件
- 5. AOF持久化
- 5.1 AOF持久化的实现
- 5.2 AOF文件的载入和还原
- 5.3 AOF文件重写
- 5.4 AOF后台重写
1.数据库
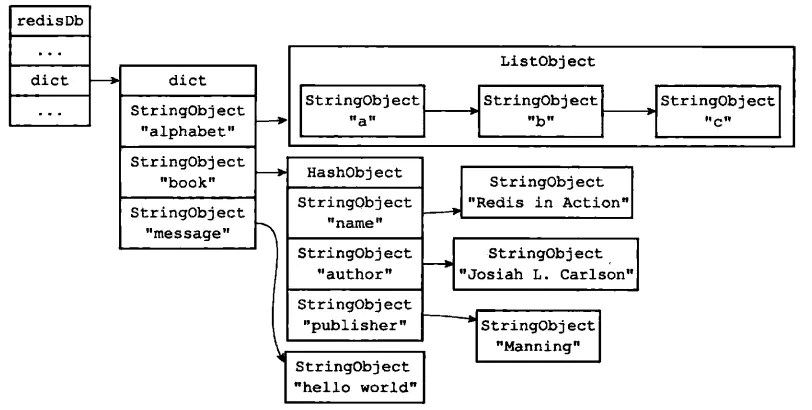
若干个数据库通过若干个dict指针来实现的。在dict下面有dbnum这个参数用来记录有几个数据库。所有的数据在数据库中都是哈希,至于这个数据是什么,是通过其指向的值来实现的。
2. 过期键
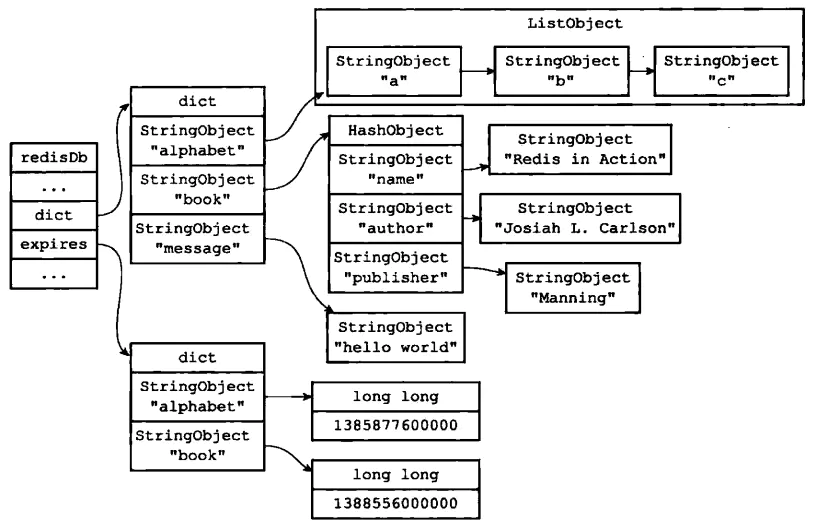
过期时间还是用字典做的,原理也很好理解。
EXPIRE设置过期时间,TTL查询过期时间,PERSIST删除过期时间。
127.0.0.1:6379> SET key value
OK
127.0.0.1:6379> EXPIRE key 1000
(integer) 1
127.0.0.1:6379> TTL key
(integer) 997
127.0.0.1:6379> TTL key
(integer) 994
127.0.0.1:6379> PERSIST key
(integer) 1
127.0.0.1:6379> TTL key
(integer) -1
3. 过期键的删除策略
定时删除:在设置键的过期时间的同时,设置一个定时器,到时自动删除;
该方法的特点是内存消耗小,CPU消耗大。因为过期键只要用完就会立刻被删除,内存消耗肯定小。但是定时器的存在,对CPU是个负担。
惰性删除:只有在调用该键的时候才会去查该键是否有效;
该方法的特点是CPU消耗小,内存消耗大。如果我要是不搜索这个键,岂不永远都不会删除了,这就是一种内存泄漏了。
定期删除:设置一个扫描时间,定期每隔一段时间扫描一部分库,删除无效键,时间和哪部分库由算法决定。
这个是上面两种的合并方式,就是时间和空间都要自己配置。
4. RDB持久化
因为redis是存在RAM中的,程序一重启就凉了,所以需要对这块内存区域做一个快照保存一下,这个就是持久化,其中RDB持久化是指指用RDB文件的方式存储。
4.1 RDB文件的创建和载入
创建有SAVE和BGSAVE两种,其中SAVE是同步的,只要执行这个操作,redis就会阻塞住数据库进行存储。BGSAVE是异步的,如果正在处理BGSAVE,此时用户又输入了SAVE或BGSAVE命令会被拒绝,因为两者的底层函数都是rdbSave(),会有竞争条件;如果BGSAVE时来的是BGREWRITEAOF,该命令会被阻塞到BGSAVE执行结束后执行;如果BGREWRITEAOF,在来BGSAVE,会被服务器拒绝的。
redis在开启服务器的时候阻塞载入RDB文件。
4.2 自动间歇性保存
自动定时调用BGSAVE。向服务器设置
save 100 6
意为100秒内执行6次数据库操作就会触发自动BGSAVE。结构依然是哈希,此次是在基础的redisServer中欧给你
struct redisServer{//...//记录了保存条件的数组struct saveparam *saveparams;//...//修改计数器long long dirty;//上次执行的时间time_t lastsave;//...
}
其中dirty用于记录上次成功执行SAVE或BGSAVE之后执行了多少次有效指令,lastsave也是,用于保存上一次成功之后的时间。有问题了,既然save的设置是100s6次,那么上次SAVE指令之后的dirty参数,就没啥意义了。奇怪。
有个类似守护进程的东西每隔100ms检查一次BGSAVE的状态,有效就执行。
4.3 读取RDB文件
直接用od -c dump.rdb查看内容。
root@ubuntu:/var/lib/redis# od -c dump.rdb
0000000 R E D I S 0 0 0 8 372 \t r e d i s
0000020 - v e r 005 4 . 0 . 9 372 \n r e d i
0000040 s - b i t s 300 @ 372 005 c t i m e 302
0000060 \n 241 K _ 372 \b u s e d - m e m 302 h
0000100 316 \f \0 372 \f a o f - p r e a m b l
0000120 e 300 \0 377 022 033 257 P i ! 003 377
0000134
root@ubuntu:/var/lib/redis# od -c dump.rdb
0000000 R E D I S 0 0 0 8 372 \t r e d i s
0000020 - v e r 005 4 . 0 . 9 372 \n r e d i
0000040 s - b i t s 300 @ 372 005 c t i m e 302
0000060 # 241 K _ 372 \b u s e d - m e m 302 260
0000100 316 \f \0 372 \f a o f - p r e a m b l
0000120 e 300 \0 376 \0 373 001 \0 \0 003 t a o \a o k
0000140 a m o t o 377 307 ' 360 240 q \v 005 031
0000156
第一个是用FLASHALL命令清掉数据库内容之后的,第二个插入了tao okamoto的字符串之后。不用特别注意这些格式,知道下里面的格式就行。
5. AOF持久化
5.1 AOF持久化的实现
RDB的持久化是将所有数据存储好,是静态的,AOF存储的是所有操作记录,是动态的。AOF更类似于比特币中的UTXO,RDB类似于以太坊中的账户。
需要注意的是,redis因为是动态的,写入文件的实时性就显得很重要了(虽然RDB也很重要的说)。众所周知,所有的write函数返回只能代表成功写入缓冲区,是否真的写入到磁盘中是不一定的,要么是满足操作系统的写入条件,要么是手动调用fasync函数写入。所以redis中有三种方式写入分别是:always、everysec和no。如果appendfsync设置为always的时候就是每来一个事件写入一次,数据肯定是最准确的,因为最多只会丢一条数据,但是效率可想而知,操作IO的效率是非常低的;everysec是判断时间的,最多只会丢1s的数据,效率比上一个高;no就是完全由操作系统决定什么时候写入内存。
5.2 AOF文件的载入和还原
AOF文件中包含了重建数据库中的所有写命令,所以只要重新执行一遍这些命令就能一模一样的还原数据库状态。和区块链中证明我有比特币时需要从头遍历一遍区块链是同样的道理。
- 创建一个不带网络的伪客户端(fake client),因为redis的命令只能在客户端上下文执行,而在如AOF文件时使用的指令直接来自AOF文件,而不是网络,所以就造了一个没有网络连接的伪客户端;
- 读取AOF中的指令;
- 使用伪客户端执行指令;
- 一直循环第2步和第2步,直至全部结束。
5.3 AOF文件重写
区块链中数据会无限上涨,所以导致链的大小也会不停上涨,比特币可以不介意,但是redis 必须介意,因此就出现了重写机制。就是将原来的多条操作和并为一条。例如,我分别执行了RPUSH model taooakmoto和RPUSH model sashaluss, AOF重新就合成一条RPUSH model taooakmoto sashaluss。
实际在执行命令时为了避免客户端输入缓冲区溢出,在重新列表、哈希、集合和有序列表这四种可能会带有多个元素的键时,会先检查数据量,如果太多,可能会有更多条指令来替代。这个很好理解。
5.4 AOF后台重写
因为AOF重写是阻塞的,而redis是单进程的,如果此时来了命令,服务器会不响应的,为了避免这种情况,redis创建了新的子进程,子进程继承了父进程的数据,进行重写写入AOF文件。
如果AOF在后台重写的时候,redis服务器接受了新的命令,这部分命令按理来说就不会写入AOF文件了,可是其实是希望能够写入的。redis的解决策略:在执行后台重写的时候,若redis服务器接受到了新的命令请求,除了服务器自己执行外,还要将这些数据写入到AOF重写缓冲区,待AOF子进程执行完毕后再去执行AOF重写缓冲区。但是如果在执行AOF重写缓冲区的时候,此时再来指令呢?我觉得会继续写入缓冲区。书上没说。