GAN(生成对抗神经网络 )的一点思考
GAN(生成对抗神经网络 )的一点思考
GAN的原理说起来很简单,就是一个生成网络,一个鉴别网络,两个网络不断对抗各自优化,道高一丈,魔高一尺,道再高一丈的过程。
那么gan到底是如何通过对抗,就可以使得随机的一张图可以生成我们想要的图片呢?
gan的目的很简单,希望构建一个从隐变量 Z 生成目标数据 X 的模型,也就是说假设了服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型 X=g(Z),这个模型能够将原来的概率分布映射到训练集的概率分布,目的就是进行分布之间的变换。
通俗的来讲,我们希望有一个模型G,可以使得输入随机分布的噪声X,而得到我们希望的分布Y,即Y=G(X), 而我们已有的标签就是希望得到的真实分布T。也就是说我们希望Y与T的分布可以越来越接近,达到同样的分布。

但是,难的就在于,我们如何去判断这个通过G构造出来的数据集,它的分布跟我们目标的数据集分布是不是一样的呢?也就是如何判断我们生成网络中生成的图与真实的图是相近的呢?
也就是求两个概率分布的相似度,有人可能会想到KL散度,但是这里不太适用,KL散度是已知两个概率分布的函数,来计算。但是这里我们并不知道它们的概率分布的表达式,也就没法用KL来计算,我们这里只知道的是一批数据。
那该怎么办呢?gan的思想就凸显出来了,既然没有合适的度量方法,那就交给网络,去学一个不就解决了吗?这也就是鉴别器的原型。
也就是构建一个网络L,输入为真实标签Z和生成器Y生成的分布,来输出两个分布之间的距离。Z是提前给定的,可以当作是网络的参数。公式简写为: Θ为参数。

同时,需要注意的是我们要的是描述分布之间的距离而不是样本的距离,而分布本身跟各个 yi 出现的顺序是没有关系的,因此分布之间的距离跟各个 yi 出现的顺序是无关的,也就是说,尽管 L 是各个 yi 的函数,但它必须全对称的!
也就是说,我们先找一个有序的函数 D,然后对所有可能的序求平均,那么就得到无序的函数了。无序的最简单实现如下图,可以简单的理解为:分布之间的距离,等于单个样本的距离的平均。
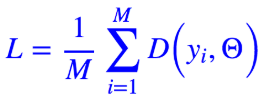
说了这么多,回归到对抗上来,对于L,我们希望当我们输入为真实分布式,L越小越好,也就是分布相同,而输入为生成的分布时,我们希望越大越好,因为L的作用就是区别不同的分布。但是对于生成网络来说,我们希望生成的分布与真实分布相同,也就是越相近越好,也就是输入到L中越小越好。这时候,gan的思想就出来了:gan!
同时,不难发现,如果对损失函数无约束的话 Loss 基本上会直接跑到负无穷去了。这也是我们不希望的。必要给 D 加点条件,一个比较容易想到的方案是约束 D 的范围,比如能不能给 D 最后的输出加个 Sigmoid 激活函数,让它取值在 0 到 1 之间?事实上这个方案在理论上是没有问题的,然而这会造成训练的困难。因为 Sigmoid 函数具有饱和区,一旦 D 进入了饱和区,就很难传回梯度来更新参数了。
所以,就引入了Lipschitz 约束。我们分析问题发现,我们距离是为了表明两个对象的差距,而如果对象产生的微小的变化,那么距离的波动也不能太大,这应该是对距离基本的稳定性要求。

至于如何加到损失函数中,就有很多的方法了。
如有错误, 欢迎各位批评指正!