对抗神经网络(一)
对抗神经网络(一)
一、对抗神经网络简介
Generative Adversative Nets启发自博弈论中的二人零和博弈,由大牛Goodfellow 开创性地提出。在二人零和博弈中,两位博弈方的利益之和为零或一个常数,即一方有所得,另一方必有所失。GAN模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当,其中生成模型G捕捉样本数据的分布,生成假样本,判别模型是一个二分类器,分辨样本是来自真实训练样本还是生成器生成的样本。原始论文地址为
https://arxiv.org/abs/1406.2661
二、基本思想
可以想象一个场景,制造假币的工具G和鉴定假币的工具D,制造假币的尽可能的使得制造出来的假币被D鉴定为真币,鉴定假币的工具D要做的就是尽可能把假币和真实货币区分开来,在G和D的不断对抗优化中,最终使得D无法鉴别出来孰真孰假,那么G制造假币的能力也到以假乱真的地步,这也就是对抗神经网络想要的结果。
生成网络的目的:生成网络是造样本的,它的目的就是使得自己造样本的能力尽可能强,强到什么程度呢,你判别网络没法判断我是真样本还是假样本。
判别网络的目的:就是能判别出来属于的样本它是来自真实样本集还是假样本集。假如输入的是真样本,网络输出就接近1,输入的是假样本,网络输出接近0,那么很完美,达到了很好判别的目的。
三,基本模型

一般来说,Generative模型和Discriminative模型都是深层神经网络,原始gan中是多层感知机模型。为了学习真实数据X上的生成器分布,在输入噪声变量Z上定义先验,然后训练Generative模型得到数据空间的映射,Discriminative模型用来计算样本来自真实数据的概率。简单来说,训练过程就是生成器G的输入为随机生成的噪音z,然后输入到Generative模型中,输出生成样本G(Z),然后输入到Discriminative模型中,得到分类输出D(z),接着把真实样本样本X输入带Discriminative模型中,得到输出D(x),Discriminative模型要把x和z区别开来,所以要使得D(x)和D(z)概率相差的尽可能的大,那么Generative模型要使得D(x)和D(z)概率相差的尽可能的的小,从而形成对抗。最终得到下列目标函数:
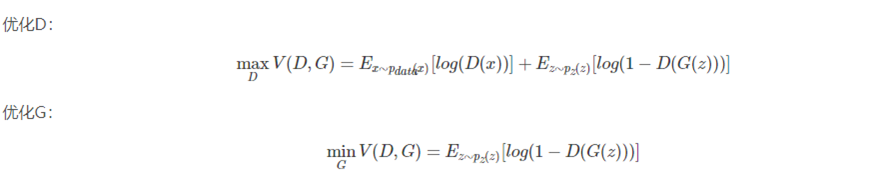
Pdata表示真实样本分布, Pz表示由生成器模拟的样本分布。
使用梯度下降法(GD)训练,那么梯度如下:
对于优化D的目标函数来说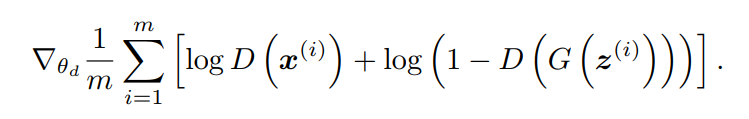
对于优化G的目标函数来说
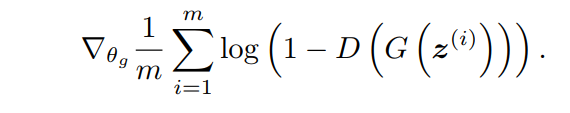
论文1中给出训练过程为

对抗神经网络收敛性的证明
首先考虑任意给定生成器G的最优鉴别器D
命题一 固定G,最优鉴别器D为
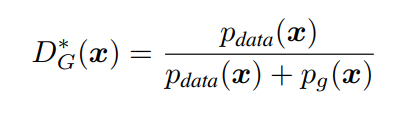
证明:根据D的目标函数为
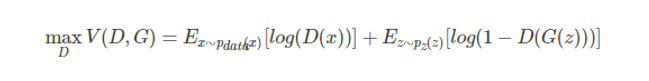
其中V(D,G) 可以表示为
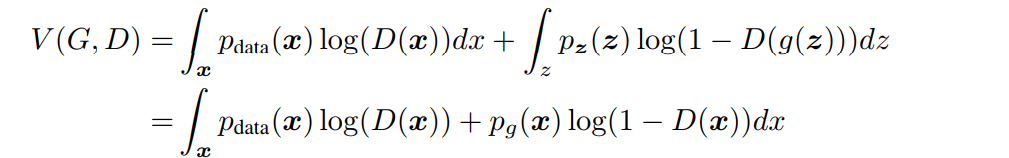
对D(x) 求导,使得导数等于0,得到目标函数最优时候的D(x)取值,即为命题一。
定理一 当且仅当Pg = Pdata时,实现了C(G)的全局最小值。此时,C(G)的值为- log 4。
根据证明一,可以对V(G,D)中最大化D的步骤进行变换,引入C(G)

在C(G)中每项log中分母除以2,公式后面加入在-log2,得到下式
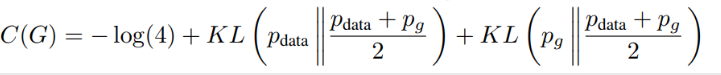
其中Kl为KL散度,又称为相对熵,把KL散度转化为JS散度
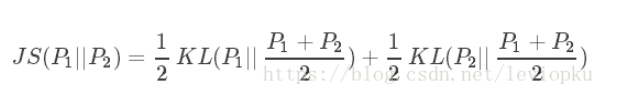
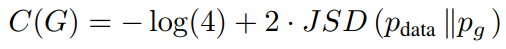
因为JS散度是非负的,当且仅当Pg = Pdata时JS散度为0,所以证明 - log(4)是C(G)的全局最小值
唯一的解决方案是Pg = Pdata,即完全复制数据分布的生成模型。
命题2 如果G和D具有足够的容量,并且在算法1的每一步,对于给定G,允许鉴别器达到其最佳,并且更新Pg,最终Pg收敛到Pdata。
证明:把V(G,D)考虑为Pg的函数,在Pg上为凸函数,根据凸函数的性质,证明了Pg收敛到Pdata
综上,就证明了对抗神经网络的收敛性,也是对抗神经网络能够应用的理论基础
训练的几个trick:
------每次进行多次D的训练,在进行G的训练,防止过拟合。
------在训练之前,可以先进行预训练。
四、几种改进的gan
1、DCGAN
DCGAN的全称是Deep Convolution Generative Adversarial Networks(深度卷积生成对抗网络),论文出处为
https://arxiv.org/abs/1511.06434
文章的初衷是,CNN在supervised learning 领域取得了非常了不起的成就(比如大规模的图片分类,目标检测等等),但是在unsupervised learning领域却没有特别大的进展。所以作者想希望能够帮助弥合CNNs在监督学习和非监督学习方面的成功。作者提出了将CNN和GAN相结合的DCGAN,并展示了它在unsupervised learning所取得的不俗的成绩。
作者将原始的Generative模型和Discriminative模型中的多层感知机用CNN进行替换,并做了如下改进:
1、all convolutional net ,它用strided convolutions替换了确定性的池化层函数(如maxpooling),在判别器DD=中使用高步长stride(一般stride=2)进行卷积操作,减小卷积之后的特征尺寸,在生成器G采用反卷积操作。
2、eliminating fully connected layers ,消除全连接层,生成器G第一层采用均匀的噪声分布Z作为输入,可称为完全连接,因为它只是一个矩阵乘法,把第一层输出reshape为一个4维张量并用作卷积层的输入。 对于鉴别器D,最后的卷积层被展平,然后输入到sigmoid得到输出。网络结构如下

把噪音z输入到全连接层100441024,然后把输出reshape成batchsize441024作为接下来卷积层的输入,采用stride =2的反卷积层,进行上采用,最终得到想要的分辨率输出,图示为64*64分辨率。
3、Use batchnorm in both the generator and the discriminator。通过将每个单元的输入归一化为零均值和单位方差来稳定学习,有助于解决由于初始化不良而导致的训练问题,并有助于深度模型中的梯度流动, 事实证明这对于让深度发生器开始学习至关重要。 然而,直接将Batchnorm应用于所有层,导致样品振荡和模型不稳定,使用在generator 和discriminator的输入层,不采用Batchnorm,可以得到很不错的效果。
4、Use ReLU activation in generator for all layers except for the output, which uses Tanh。在generator 中,除了最终输出层使用tanh,全部使用relu激活函数。作者观察到,使用有界激活可以使模型更快地学习饱和和覆盖训练分布的颜色空间。
5、Use LeakyReLU activation in the discriminator for all layers。
下面附上DCGAN生成手写数字mnist的代码
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import os
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.layers.python.layers import batch_norm as batch_norm
import timemnist = input_data.read_data_sets('../../MNIST_data', one_hot=True)
BATCH_SIZE = 16
Z_dim = 100def batch_normal(inputs,is_train = True ,name = 'batch_normal'):#try:if is_train:return batch_norm(inputs, decay = 0.9, epsilon = 1e-5, scale = True,is_training = is_train, updates_collections = None)else :return batch_norm(inputs, decay = 0.9, epsilon = 1e-5, scale = True,is_training = is_train, reuse = True,updates_collections = None)def linear_layer(value, output_dim, name = 'linear_connected'):with tf.variable_scope(name):try:weights = tf.get_variable('weights', [int(value.get_shape()[1]), output_dim], initializer = tf.truncated_normal_initializer(stddev = 0.02)) #weight的复用,不存在时创建weight,存在时直接获取weightbiases = tf.get_variable('biases', [output_dim], initializer = tf.constant_initializer(0.0))except ValueError:tf.get_variable_scope().reuse_variables()weights = tf.get_variable('weights', [int(value.get_shape()[1]), output_dim], initializer = tf.truncated_normal_initializer(stddev = 0.02))biases = tf.get_variable('biases', [output_dim], initializer = tf.constant_initializer(0.0))return tf.matmul(value, weights) + biasesdef conv2d(value, output_dim, k_h = 5, k_w = 5, strides = [1,1,1,1], name = "conv2d"):with tf.variable_scope(name):try:weights = tf.get_variable('weights', [k_h, k_w, int(value.get_shape()[-1]), output_dim],initializer = tf.truncated_normal_initializer(stddev = 0.02))biases = tf.get_variable('biases',[output_dim], initializer = tf.constant_initializer(0.0))except ValueError:tf.get_variable_scope().reuse_variables()weights = tf.get_variable('weights', [k_h, k_w, int(value.get_shape()[-1]), output_dim],initializer = tf.truncated_normal_initializer(stddev = 0.02))biases = tf.get_variable('biases',[output_dim], initializer = tf.constant_initializer(0.0))conv = tf.nn.conv2d(value, weights, strides = strides, padding = "SAME")return tf.nn.bias_add(conv, biases)def deconv2d(value, output_shape, k_h = 5, k_w = 5, strides = [1,1,1,1], name = "deconv2d"):with tf.variable_scope(name):try:weights = tf.get_variable('weights',[k_h, k_w, output_shape[-1], int(value.get_shape()[-1])],initializer = tf.truncated_normal_initializer(stddev = 0.02))biases = tf.get_variable('biases',[output_shape[-1]], initializer = tf.constant_initializer(0.0))except ValueError:tf.get_variable_scope().reuse_variables()weights = tf.get_variable('weights',[k_h, k_w, output_shape[-1], int(value.get_shape()[-1])],initializer = tf.truncated_normal_initializer(stddev = 0.02))biases = tf.get_variable('biases',[output_shape[-1]], initializer = tf.constant_initializer(0.0))deconv = tf.nn.conv2d_transpose(value, weights, output_shape, strides = strides)return tf.nn.bias_add(deconv, biases)def conv_cond_concat(value1, value2, concat_dim, name = 'concat'):#矩阵相加value1_shapes = value1.get_shape().as_list()value2_shapes = value2.get_shape().as_list()with tf.variable_scope(name):if concat_dim == 1:return tf.concat([value1,value2],1,name)if concat_dim == 3:return tf.concat([value1, value2 * tf.ones(value1_shapes[0:3] + value2_shapes[3:])], 3, name = name)def lrelu(x, leak = 0.2, name = 'lrelu'): return tf.maximum(x, x*leak, name = name)def generator(z, y, train = True):#添加标签yb = tf.reshape(y, [BATCH_SIZE, 1, 1, 10], name = 'g_yb')z = conv_cond_concat(z, y, 1, name = 'g_z_concat_y')#拼接上标签linear1 = linear_layer(z,64*7*7, name = 'g_linear_layer1')bn1 = tf.nn.relu(batch_normal(linear1, is_train = True, name = 'g_bn1'))bn1_re = tf.reshape(bn1, [BATCH_SIZE, 7, 7, 64], name = 'g_bn1_reshape')bn1_re = conv_cond_concat(bn1_re, yb,3, name = 'g_bn2_re_concat_yb')deconv1 = deconv2d(bn1_re, [BATCH_SIZE, 14, 14, 32], strides = [1, 2, 2, 1], name = 'g_deconv1')bn2 = tf.nn.relu(batch_normal(deconv1, is_train = True, name = 'g_bn3'))bn2 = conv_cond_concat(bn2, yb, 3,name = 'g_bn3_re_concat_yb')deconv2 = deconv2d(bn2, [BATCH_SIZE, 28, 28, 1], strides = [1, 2, 2, 1], name = 'g_deconv2')deconv2 = tf.reshape(deconv2,[BATCH_SIZE,784])return tf.nn.sigmoid(deconv2)def discriminator(image ,y,reuse = False):if reuse:tf.get_variable_scope().reuse_variables() #第二次调用discriminator取得判别器判别的生成的手写数字的结果不生成新的网络,使用的是同一个网络yb = tf.reshape(y, [BATCH_SIZE, 1, 1, 10], name = 'd_yb')# add condition image_ = tf.reshape(image, [-1,28, 28,1])image_ = conv_cond_concat(image_, yb,3, name = 'd_image_concat_yb')conv1 = conv2d(image_, 32, strides = [1,2, 2, 1], name = 'd_conv1')bn1 = batch_normal(conv1, is_train = True, name = 'd_bn1')lr1 = lrelu(bn1, name = 'd_lrelu1')lr1 = conv_cond_concat(lr1, yb, 3,name = 'd_lr1_concat_yb')conv2 = conv2d(lr1, 64, strides = [1, 2, 2, 1], name = 'd_conv2')bn2 = batch_normal(conv2, is_train = True, name = 'd_bn2')lr2 = lrelu(bn2, name = 'd_lrelu2')lr2_re = tf.reshape(lr2, [-1, 7*7*64], name = 'd_lr2_reshape')lr2_re = conv_cond_concat(lr2_re, y, 1, name = 'd_lr2re_concat_y')linear2 = linear_layer(lr2_re, 1, name = 'd_linear_layer2')linear2 = lrelu(linear2, name = 'd_lrelu3')return linear2def plot(samples): #保存图片时使用的plot函数fig = plt.figure(figsize=(4, 4)) #初始化一个4行4列包含16张子图像的图片gs = gridspec.GridSpec(4, 4) #调整子图的位置gs.update(wspace=0.05, hspace=0.05) #置子图间的间距for i, sample in enumerate(samples): #依次将16张子图填充进需要保存的图像ax = plt.subplot(gs[i])plt.axis('off')ax.set_xticklabels([])ax.set_yticklabels([])ax.set_aspect('equal')plt.imshow(sample.reshape(28, 28), cmap='Greys_r')return figdef sample_Z(m, n): #生成维度为[m, n]的随机噪声作为生成器G的输入return np.random.uniform(-1., 1., size=[m, n])tf.reset_default_graph()X = tf.placeholder(tf.float32, shape=[BATCH_SIZE, 784]) #X表示真的样本(即真实的手写数字)
Y = tf.placeholder(tf.float32, shape=[BATCH_SIZE, 10])
Z = tf.placeholder(tf.float32, shape=[BATCH_SIZE, Z_dim]) #Z表示生成器的输入(在这里是噪声),是一个N列100行的矩阵
G_sample = generator(Z,Y) #取得生成器的生成结果D_logit_real = discriminator(X,Y) #取得判别器判别的真实手写数字的结果
D_logit_fake = discriminator(G_sample,Y) #取得判别器判别的生成的手写数字的结果D_loss_real = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_real, labels=tf.ones_like(D_logit_real))) #对判别器对真实样本的判别结果计算误差(将结果与1比较)
D_loss_fake = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.zeros_like(D_logit_fake))) #对判别器对虚假样本(即生成器生成的手写数字)的判别结果计算误差(将结果与0比较)
D_loss = D_loss_real + D_loss_fake #判别器的误差
G_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=D_logit_fake, labels=tf.ones_like(D_logit_fake))) #生成器的误差(将判别器返回的对虚假样本的判别结果与1比较)t_vars = tf.trainable_variables()
d_vars = [var for var in t_vars if 'd_' in var.name]#获取命名空间里带有d_的所有变量g_vars = [var for var in t_vars if 'g_' in var.name]D_optimizer = tf.train.AdamOptimizer(1e-4).minimize(D_loss,var_list = d_vars) #判别器的训练器
G_optimizer = tf.train.AdamOptimizer(1e-4).minimize(G_loss,var_list = g_vars) #生成器的训练器i = 0with tf.Session() as sess:sess.run(tf.global_variables_initializer())for it in range(100000):X_mb, Y_mb = mnist.train.next_batch(BATCH_SIZE)_, D_loss_curr = sess.run([D_optimizer, D_loss], feed_dict={X: X_mb, Y:Y_mb, Z: sample_Z(BATCH_SIZE, Z_dim)})_, G_loss_curr = sess.run([G_optimizer, G_loss], feed_dict={Y:Y_mb,Y:Y_mb,Z: sample_Z(BATCH_SIZE, Z_dim)})#依次训练判别器和生成器if it % 1000 == 0:#保存训练图片samples = sess.run(G_sample, feed_dict={Y:Y_mb, Z: sample_Z(BATCH_SIZE, Z_dim)}) # 16*784fig = plot(samples)plt.savefig('out/{}.png'.format(str(i).zfill(4)), bbox_inches='tight')i += 1plt.close(fig)if it % 1000 == 0:localtime = time.asctime( time.localtime(time.time()) )print('Iter: {}'.format(it),)print('time is'+str(localtime))print('D loss: {:.4}'.format(D_loss_curr))print('G loss: {:.4}'.format(G_loss_curr))print()
训练结果



2、WGAN
参考博客和论文地址
https://zhuanlan.zhihu.com/p/25071913
https://arxiv.org/abs/1701.07875
与DCGAN不同,WGAN主要从损失函数的角度对GAN做了改进,损失函数改进之后的WGAN即使在全链接层上也能得到很好的表现结果,WGAN对GAN的改进主要有:
– 判别器最后一层去掉sigmoid
– 生成器和判别器的loss不取log
– 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
– 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
WGAN理论上给出了GAN训练不稳定的原因,即交叉熵(JS散度)不适合衡量具有不相交部分的分布之间的距离,转而使用wassertein距离去衡量生成数据分布和真实数据分布之间的距离,理论上解决了训练不稳定的问题。具体细节参考博客和原论文。在这里就简单讨论下原始gan的问题所在:
在前面我们证明了在最优判别器D时,
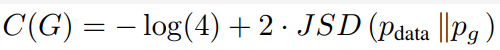
也就是在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布Pdata与生成分布Pg之间的JS散度,如果两个分布之间越接近它们的JS散度越小,我们通过优化JS散度就能将Pg拉向Pdata,最终以假乱真,问题就出在这个JS散度上。这个希望在两个分布有所重叠的时候是成立的,但是如果两个分布完全没有重叠的部分,或者它们重叠的部分可忽略,它们的JS散度是一个常数log 2,而这对于梯度下降方法意味着——梯度为0,此时对于最优判别器来说,生成器肯定是得不到一丁点梯度信息的;即使对于接近最优的判别器来说,生成器也有很大机会面临梯度消失的问题。最后原始GAN不稳定的原因就彻底清楚了:判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。
所以作者使用了wassertein距离去衡量生成数据分布和真实数据分布之间的距离,相对KL散度与JS散度具有优越的平滑特性,理论上可以解决梯度消失问题,并且通过数学变换将Wasserstein距离写成可求解的形式,但是需要加上Lipschitz连续限制。Lipschitz限制是在样本空间中,要求判别器函数D(x)梯度值不大于一个有限的常数K,通过权重值限制的方式保证了权重参数的有界性,作者采用weight clipping,即每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c,从而达到目的。
改进之后的WGAN的两个loss为
G_loss:
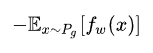
D_loss:
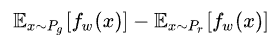
注意原始GAN的判别器做的是真假二分类任务,所以最后一层是sigmoid,但是现在WGAN中的判别器f_w做的是近似拟合Wasserstein距离,属于回归任务,所以要把最后一层的sigmoid拿掉。同时作者发现如果使用Adam,判别器的loss有时候会崩掉,当它崩掉时,Adam给出的更新方向与梯度方向夹角的cos值就变成负数,更新方向与梯度方向南辕北辙,这意味着判别器的loss梯度是不稳定的,所以不适合用Adam这类基于动量的优化算法。作者改用RMSProp之后,问题就解决了,因为RMSProp适合梯度不稳定的情况。所以作者在原始gan的基础上改进了四点,这个前面开始已经提到了。
最终wgan通过简单的改进,成功地做到了以下几点:
– 彻底解决GAN训练不稳定的问题,不再需要小心平衡生成器和判别器的训练程度
– 基本解决了collapse mode的问题,确保了生成样本的多样性
– 训练过程中终于有一个像交叉熵、准确率这样的数值来指示训练的进程,这个数值越小代表GAN训练得越好,代表生成器产生的图像质量越高(如题图所示)
– 不需要精心设计的网络架构,最简单的多层全连接网络就可以做到
附上wgan loss代码:
def G_wgan(G, D, opt, training_set, minibatch_size): # pylint: disable=unused-argumentlatents = tf.random_normal([minibatch_size] + G.input_shapes[0][1:])labels = training_set.get_random_labels_tf(minibatch_size)fake_images_out = G.get_output_for(latents, labels, is_training=True)fake_scores_out = fp32(D.get_output_for(fake_images_out, labels, is_training=True))loss = -fake_scores_outreturn lossdef D_wgan(G, D, opt, training_set, minibatch_size, reals, labels, # pylint: disable=unused-argumentwgan_epsilon = 0.001): # Weight for the epsilon term, \epsilon_{drift}.latents = tf.random_normal([minibatch_size] + G.input_shapes[0][1:])fake_images_out = G.get_output_for(latents, labels, is_training=True)real_scores_out = fp32(D.get_output_for(reals, labels, is_training=True))fake_scores_out = fp32(D.get_output_for(fake_images_out, labels, is_training=True))loss = fake_scores_out - real_scores_outreturn loss
3、WGAN-gp
论文地址和参考博客
https://arxiv.org/abs/1704.00028
https://www.zhihu.com/question/52602529/answer/158727900
WGAN-GP是WGAN之后的改进版,主要还是改进了连续性限制的条件,因为,作者也发现将权重剪切到一定范围之后,比如剪切到[-0.01,+0.01]后,发生了这样的情况

判别器中所有网络参数的数值分布,集中在最大和最小两个极端上,造成了对神经网络强大拟合能力的巨大浪费,同时判别器没能充分利用自身的模型能力,经过它回传给生成器的梯度也会跟着变差,也就是判别器训练得不好,生成器梯度不准,四处乱跑。并且,强制剪切权重容易导致梯度消失或者梯度爆炸,原因是判别器是一个多层网络,如果我们把clipping threshold设得稍微小了一点,每经过一层网络,梯度就变小一点点,多层之后就会指数衰减;反之,如果设得稍微大了一点,每经过一层网络,梯度变大一点点,多层之后就会指数爆炸。
为了解决这个问题,并且找一个合适的方式满足lipschitz连续性条件,作者提出了使用梯度惩罚(gradient penalty)的方式以满足此连续性条件,通过设置一个额外的loss项来对梯度超过k进行惩罚。加上的惩罚项为:
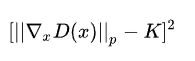
得到新的判别器loss为
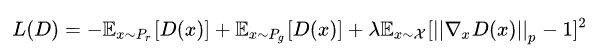
3个loss项都是期望的形式,落到实现上得变成采样的形式。前面两个期望的采样我们都熟悉,第一个期望是从真样本集里面采,第二个期望是从生成器的噪声输入分布采样后,再由生成器映射到样本空间。可是第三个分布要求我们在整个样本空间 上采样,这完全不科学!由于所谓的维度灾难问题,如果要通过采样的方式在图片或自然语言这样的高维样本空间中估计期望值,所需样本量是指数级的,实际上没法做到。所以,论文作者就非常机智地提出,我们其实没必要在整个样本空间上施加Lipschitz限制,只要重点抓住生成样本集中区域、真实样本集中区域以及夹在它们中间的区域就行了。具体来说,我们先随机采一对真假样本,还有一个0-1的随机数:
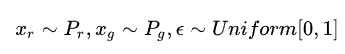
然后在 x_r 和 x_g 的连线上随机插值采样:
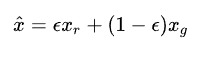
然后把随机插值得到的样本带入梯度惩罚项,得到最终loss,这时候再统计判别器中所有网络参数的数值分布,参数的数值分布明显就合理得多了,判别器也能够充分利用自身模型的拟合能力。

接下来附上wgan-gp loss代码
def D_wgan_gp(G, D, opt, training_set, minibatch_size, reals, labels, wgan_lambda = 10.0, # Weight for the gradient penalty term.wgan_target = 1.0): # Target value for gradient magnitudes.latents = tf.random_normal([minibatch_size] + G.input_shapes[0][1:])fake_images_out = G.get_output_for(latents, labels, is_training=True)real_scores_out = fp32(D.get_output_for(reals, labels, is_training=True))fake_scores_out = fp32(D.get_output_for(fake_images_out, labels, is_training=True))loss = fake_scores_out - real_scores_outwith tf.name_scope('GradientPenalty'):mixing_factors = tf.random_uniform([minibatch_size, 1, 1, 1], 0.0, 1.0, dtype=fake_images_out.dtype)mixed_images_out = tflib.lerp(tf.cast(reals, fake_images_out.dtype), fake_images_out, mixing_factors)mixed_scores_out = fp32(D.get_output_for(mixed_images_out, labels, is_training=True))mixed_loss = opt.apply_loss_scaling(tf.reduce_sum(mixed_scores_out))mixed_grads = opt.undo_loss_scaling(fp32(tf.gradients(mixed_loss, [mixed_images_out])[0]))mixed_norms = tf.sqrt(tf.reduce_sum(tf.square(mixed_grads), axis=[1,2,3]))mixed_norms = autosummary('Loss/mixed_norms', mixed_norms)gradient_penalty = tf.square(mixed_norms - wgan_target)loss += gradient_penalty * (wgan_lambda / (wgan_target**2))return loss以上为个人学习总结,参考了不少大佬博客,写的若有错误之处,欢迎大家批评指正!